Evaluation Runs
Run metrics over a dataset version — optionally piping each row through a workflow first — and read, download, or rerun the results.
An evaluation run takes a released dataset version, optionally executes a workflow for every row, and scores the results with your metrics. Start runs from the EVALUATIONS tab of Evaluations.
Start a run from the UI
Open the run dialog
On Evaluations → EVALUATIONS, click Run evaluation. The New Evaluation Run sheet opens.
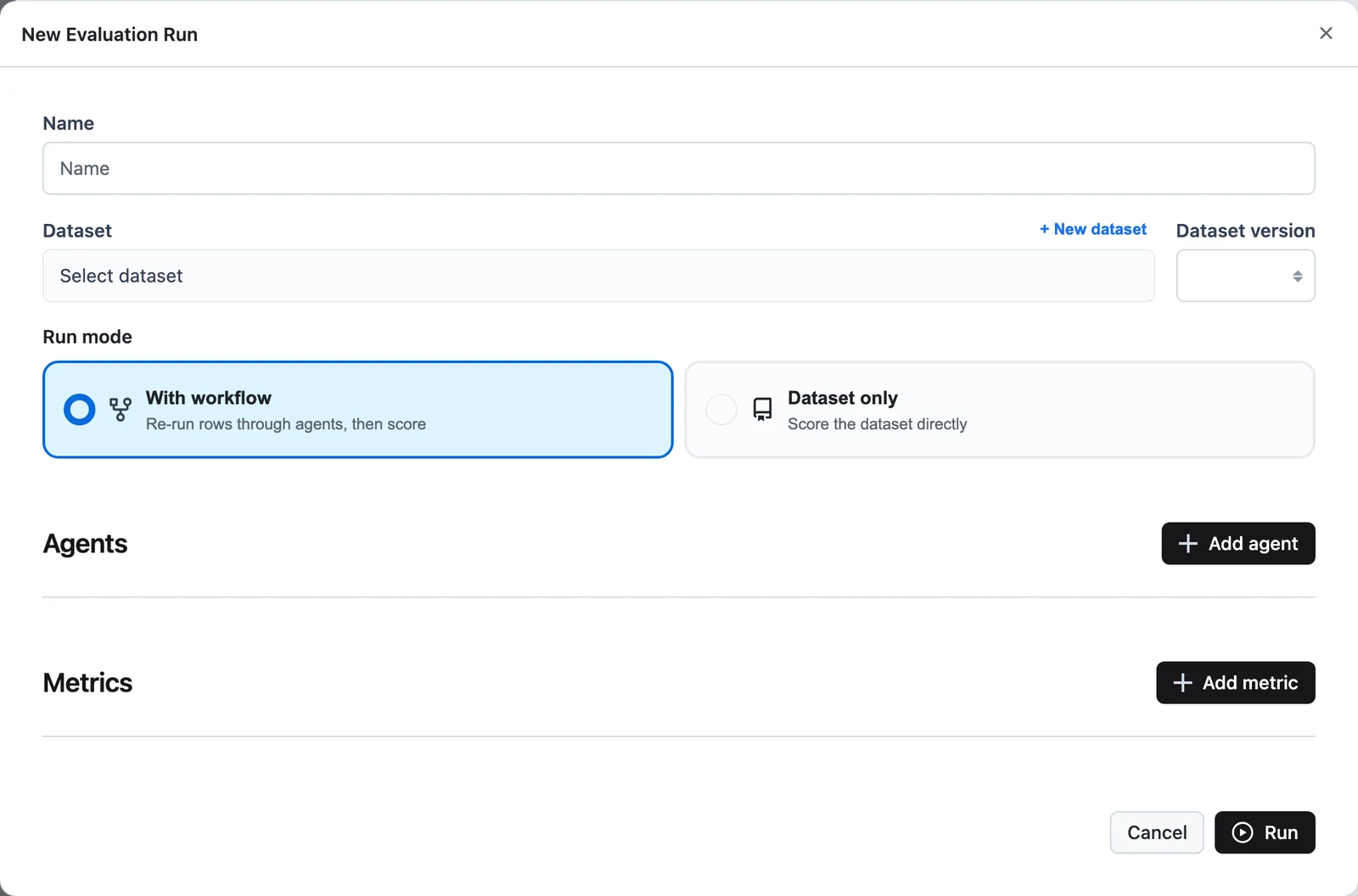
Name it and pick the data
Enter a Name, then choose a Dataset and Dataset version. Only datasets with at least one released version appear — release a draft first if yours is missing (see Datasets).
Choose the run mode
- With workflow — Re-run rows through agents, then score. Each dataset row is fed into one or more workflows, and metrics can score the fresh outputs.
- Dataset only — Score the dataset directly. No workflow executes; metrics read the stored fields. Use this for datasets built from traces or precomputed outputs.
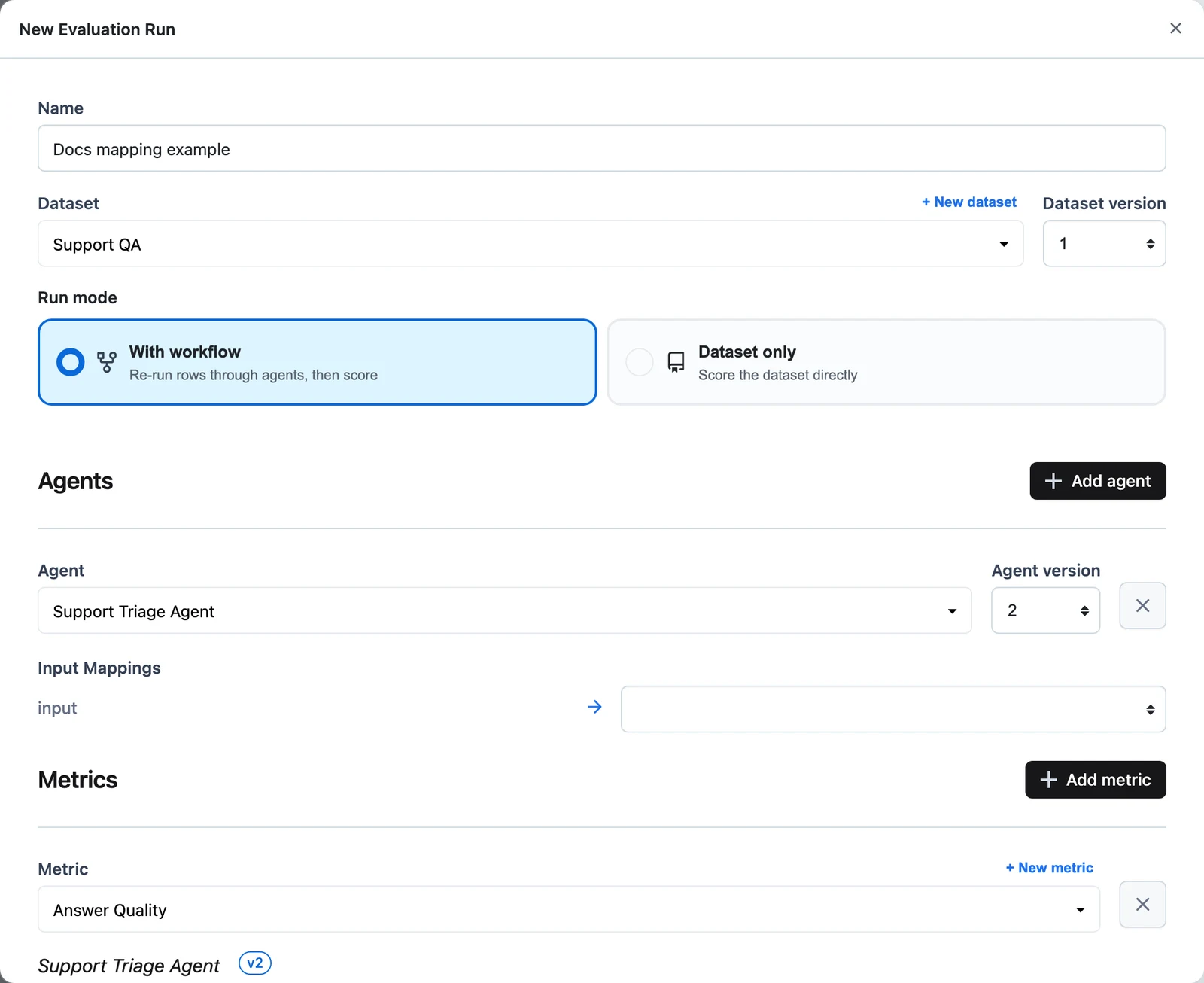
(With workflow) add agents
Click Add agent and pick a workflow (Agent) and an Agent version. Then map the workflow's inputs: each input parameter gets a selector drawn from your dataset columns, like $.dataset.question.
Add metrics and map their inputs
Click Add metric and pick a saved Metric. For every metric input, choose a source:
$.dataset.<column>— a dataset field.$.workflow.<output>— an output of a workflow added in the previous step (with-workflow mode).$.trace— the full recorded trace, offered in dataset-only mode when items carryinput,output,status, andtrace_idfields.
Run and watch the results
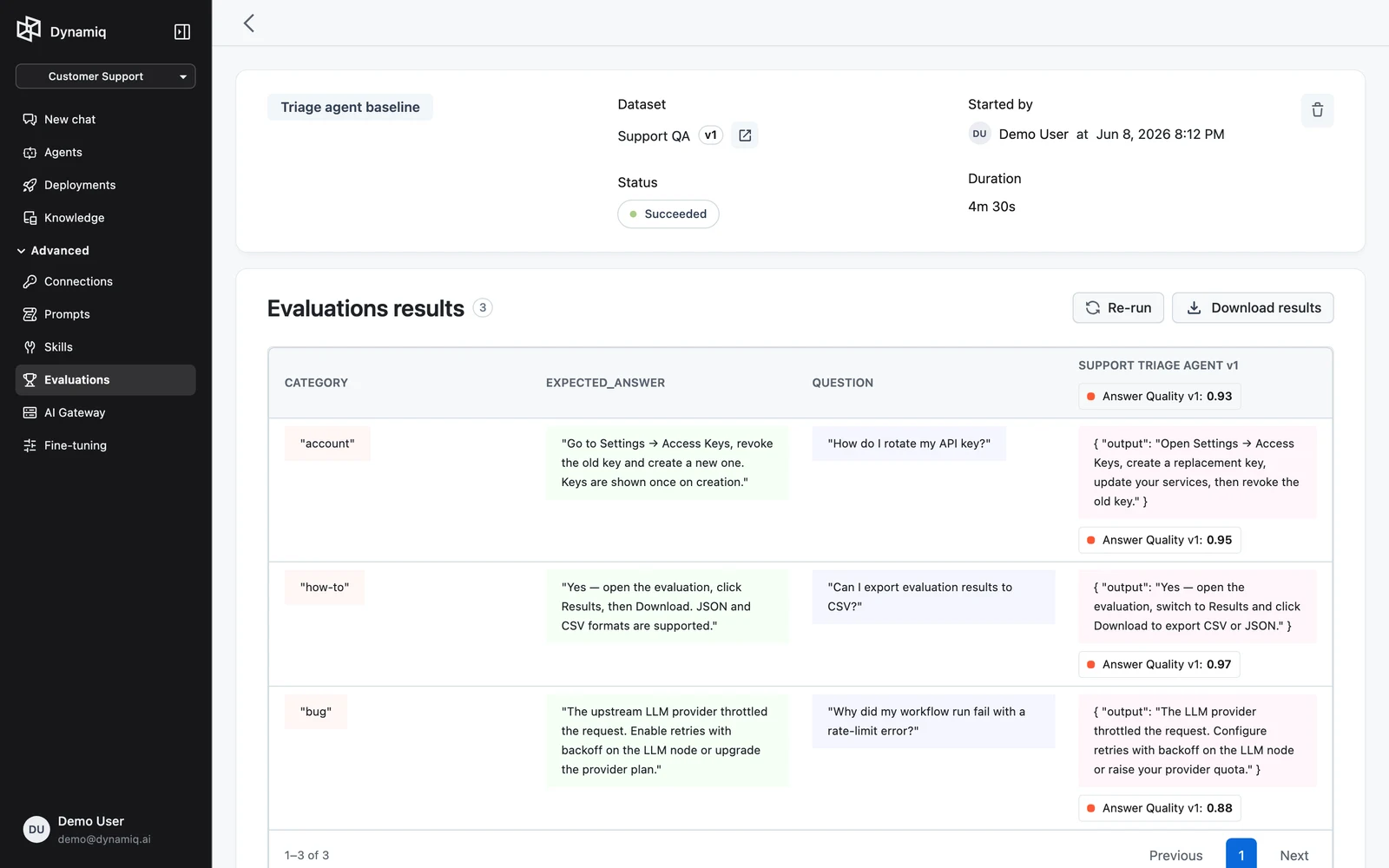
Start the run. It appears in the runs list with NAME, STATUS, STARTED BY, and STARTED AT columns; statuses progress through pending, running, and end at succeeded, failed, or canceled.
Open the run to see the Evaluations results table: one row per dataset item with the item's fields and one column per metric score, plus run status. Click Download results to save the full result set as JSON (disabled while the run is still running).
Rerunning is for recovery, not variation: rerun re-executes only the failed tasks of a run, keeping the original metric and workflow versions pinned. If nothing failed, the API responds with "No failed tasks to rerun." To evaluate a changed workflow or metric, start a new run.
Start a run via the API
POST /v1/evaluations starts a run. config is a list of entries, each pairing an optional workflow with the metrics that score it; omit workflow for a dataset-only run. Input mappings use the same input_transformer.selector syntax as the UI:
curl -X POST "https://api.getdynamiq.ai/v1/evaluations" \
-H "Authorization: Bearer $DYNAMIQ_PAT" \
-H "Content-Type: application/json" \
-d '{
"name": "rag-v2-vs-regression-set",
"project_id": "<your-project-id>",
"dataset_id": "<dataset-id>",
"dataset_version_id": "<released-version-id>",
"config": [
{
"workflow": {
"id": "<workflow-id>",
"version_id": "<workflow-version-id>",
"input_transformer": {
"selector": {
"question": "$.dataset.question",
"context": "$.dataset.context"
}
}
},
"metrics": [
{
"id": "<metric-id>",
"input_transformer": {
"selector": {
"questions": "$.dataset.question",
"ground_truth_answers": "$.dataset.ground_truth_answer",
"answers": "$.workflow.answer"
}
}
}
]
}
]
}'Each metric entry may also pin a version_id; without it the metric's latest version is captured at start time so the stored config stays stable for reruns.
Read and manage runs:
# List runs / get one
curl "https://api.getdynamiq.ai/v1/evaluations?project_id=<your-project-id>" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
curl "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
# Per-row results (paginated) and metric summaries
curl "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>/results" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
curl "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>/metrics" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
# Download everything as a JSON file
curl -OJ "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>/results/download" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
# Rerun failed tasks / delete a run
curl -X POST "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>/rerun" \
-H "Authorization: Bearer $DYNAMIQ_PAT"
curl -X DELETE "https://api.getdynamiq.ai/v1/evaluations/<evaluation-id>" \
-H "Authorization: Bearer $DYNAMIQ_PAT"Next steps
API reference: Evaluations
The full REST contract for starting, inspecting, and downloading evaluation runs.
Metrics
Tune rubrics and code metrics before wiring them into runs.
Datasets
Release the dataset versions your runs will score.
Versions & Releases
Understand the workflow versions an evaluation pins.